I have your social security number

I'm an avid hoarder of data. It’s a problem - a pretty bad one, honestly. And a bit expensive. But nonetheless, I continue my journey of downloading terabytes upon terabytes of databases, eBooks, and web scrapes. Why? Because I can.
I also like to know what information of mine is available online. And I don’t trust services such as Have I Been Pwned to be as absolutely comprehensive as possible. Although don't get me wrong, Troy Hunt is far more thorough with his job and research than I'll ever be, I'm just paranoid.
A Revitalization of My Love
On August 6th, 2024, a user from Breached Forums posted a thread titled NationalPublicData full db 2024, and with it, documents containing nearly three billion records of PII (personally identifiable information).
Fenice appears to be an alt for USDoD, the original poster of the database.
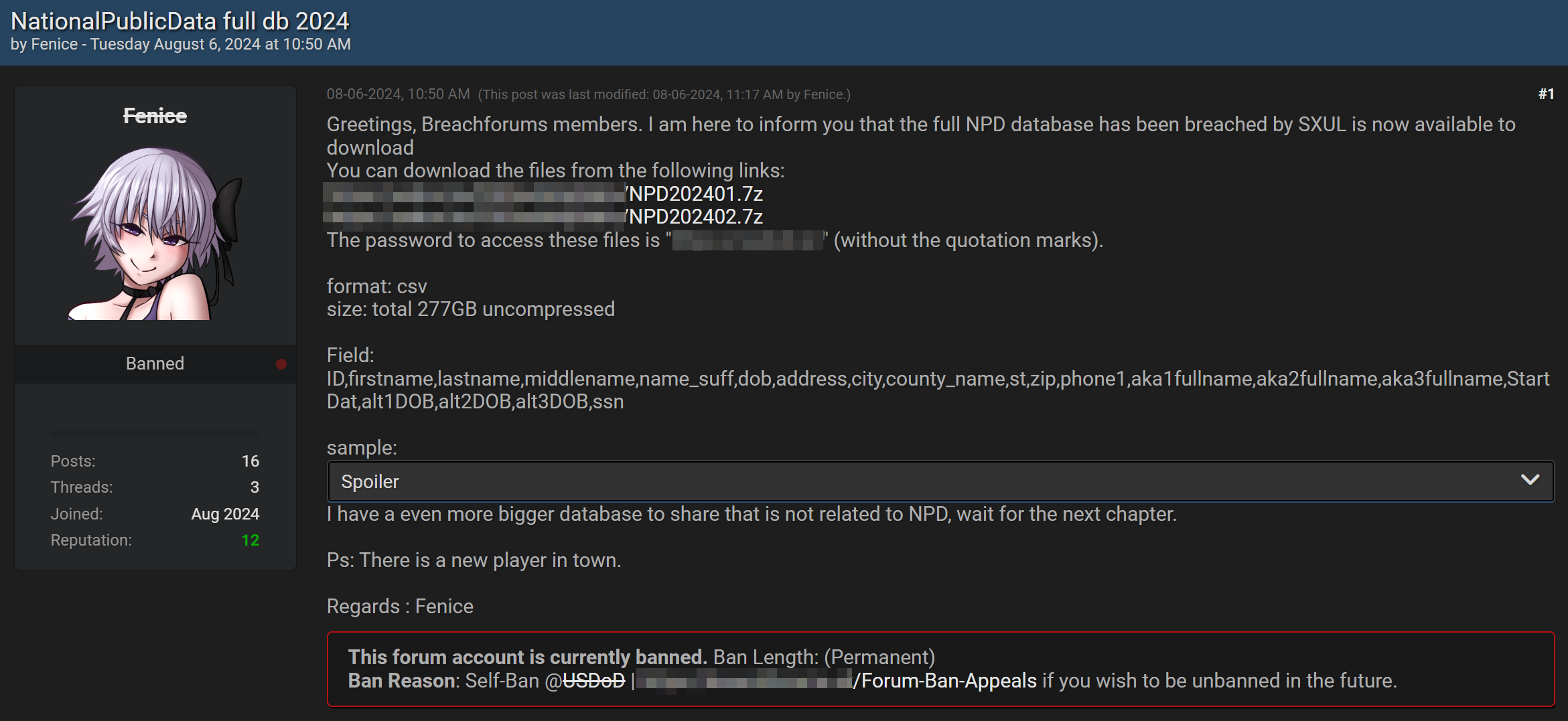
The breach comes from National Public Database, a data aggregation company you've probably never heard of. They hold information pertaining to, according to their homepage:
Criminal Records, Background Checks and more. Our services are currently used by investigators, background check websites, data resellers, mobile apps, applications and more.
A class action lawsuit has opened up against NPD, claiming that the business utilized non-public records in order to scrape data from billions of individuals. While there's the claim that people who utilized opt-out services are not included in the database, this is an immoral tactic that could disregard that requirement entirely.
While I haven’t done much in the realm of data aggregation or leak collection over the last year or so, seeing this made my mouth water. It was a gold mine I’d been hunting for in previous leaks, that would help bring all my data together in a neat, coherent way. So of course, I downloaded it (after finding a torrent, for better speeds). And don't worry, I'm not a monster or anything - I made sure to seed it, and it’s currently sitting at a 5.0 ratio. If you’d like the download, message me on either Discord @nekojesus or Twitter @SophiaTheChrist if you’re too lazy to hunt it down yourself.
Starting the Project
I decided to use this opportunity as an excuse to finally begin working on a project that’s been on the back burner for years - an elegant solution for quickly and efficiently referencing my dragon’s hoard of PII. It’s nice to get out of the rut every now and then and put together some kind of project, even if it’s a fairly simple Node.js data aggregation project.
After clearing out some long-ago-watched anime to make space for the damn near 750 GB of data I was about to accumulate, I got to work with my standard toolset:
- MongoDB: A perfect back-end solution for massive databases like this. I began using it around 2019 and fell in love with the similarities it has with pure JSON formats, and I haven’t gone back to SQL since.
- Node.js: Yeah yeah, JavaScript sucks. But it’s quick, easy, and doesn’t yell at me for disobeying its personal space. It’s my primary language whenever I’m building pretty much anything dedicated to the web or data structures.
- Tailwind CSS: Not much for front-end design, I like when things are easy to deal with. Having been a Bootstrap addict once-upon-time, Tailwind is a perfect successor for the modern day.
- VSCode: I hate Microsoft; they have a nice IDE though.
Getting the Data
For the back-end, I needed two programs. One for formatting and getting the data into MongoDB, the other for the server itself which would be running the search and querying the database. In an effort to make these more modular for the different types of databases I have, and to future-proof a bit for when more get merged into this primary collection later on, the intention was to keep things simple.
I failed at that.
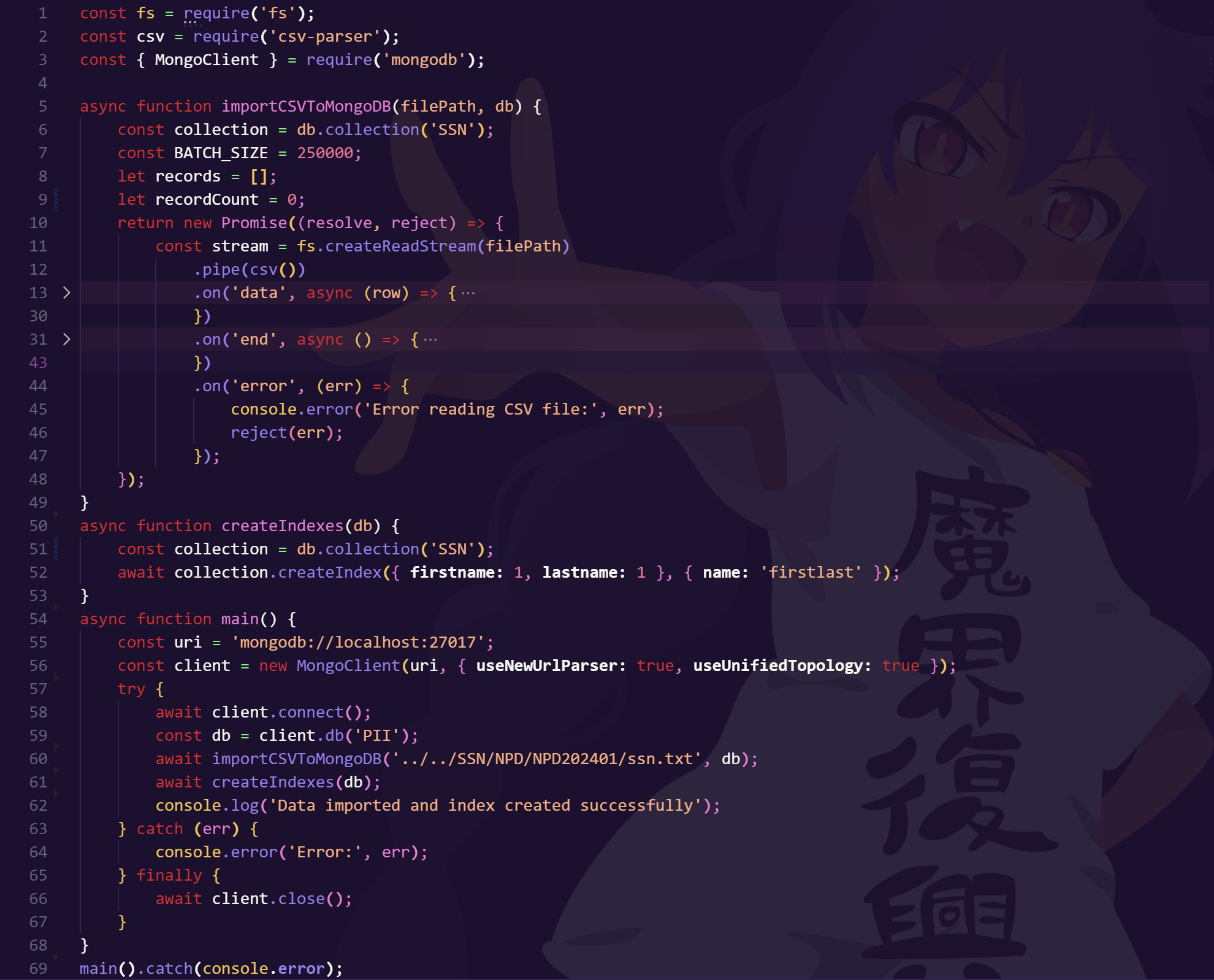
If you can determine anything from that snippet there, it’s that my code tends to be a bit haphazard and a little too hard-coded to allow for modular input. Moving on, I’m likely to add arguments for inputting the specific file I want it to target, as well as arguments for which indexes to create (potentially collection names as well, as currently it seems to have a lot of issues inputting new data after already previously making such large indexes). For now, this works for me at least, although it needs a lot more database management to be the cohesive tool I’d like for aggregating everything in my collection.
Using The Data
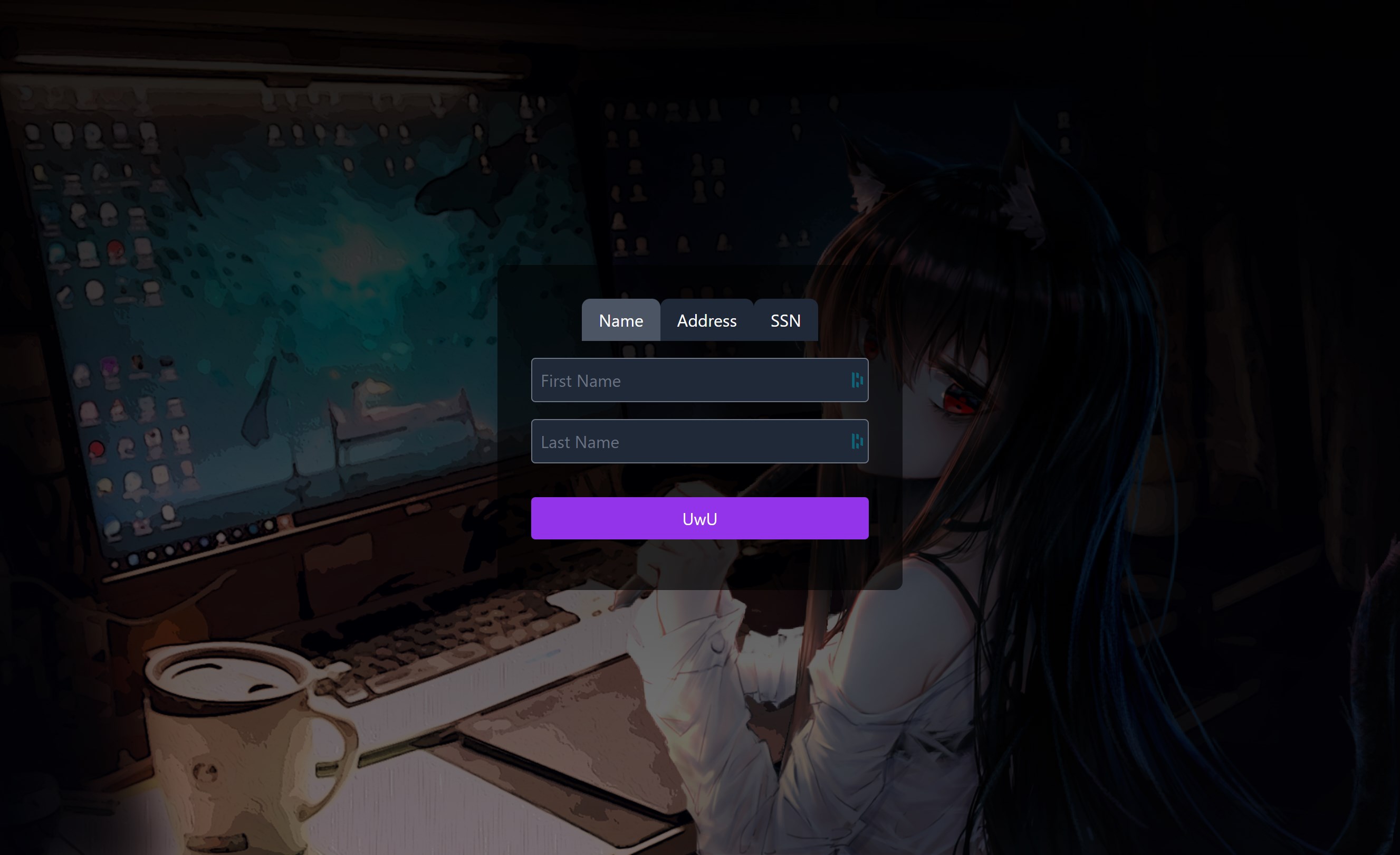
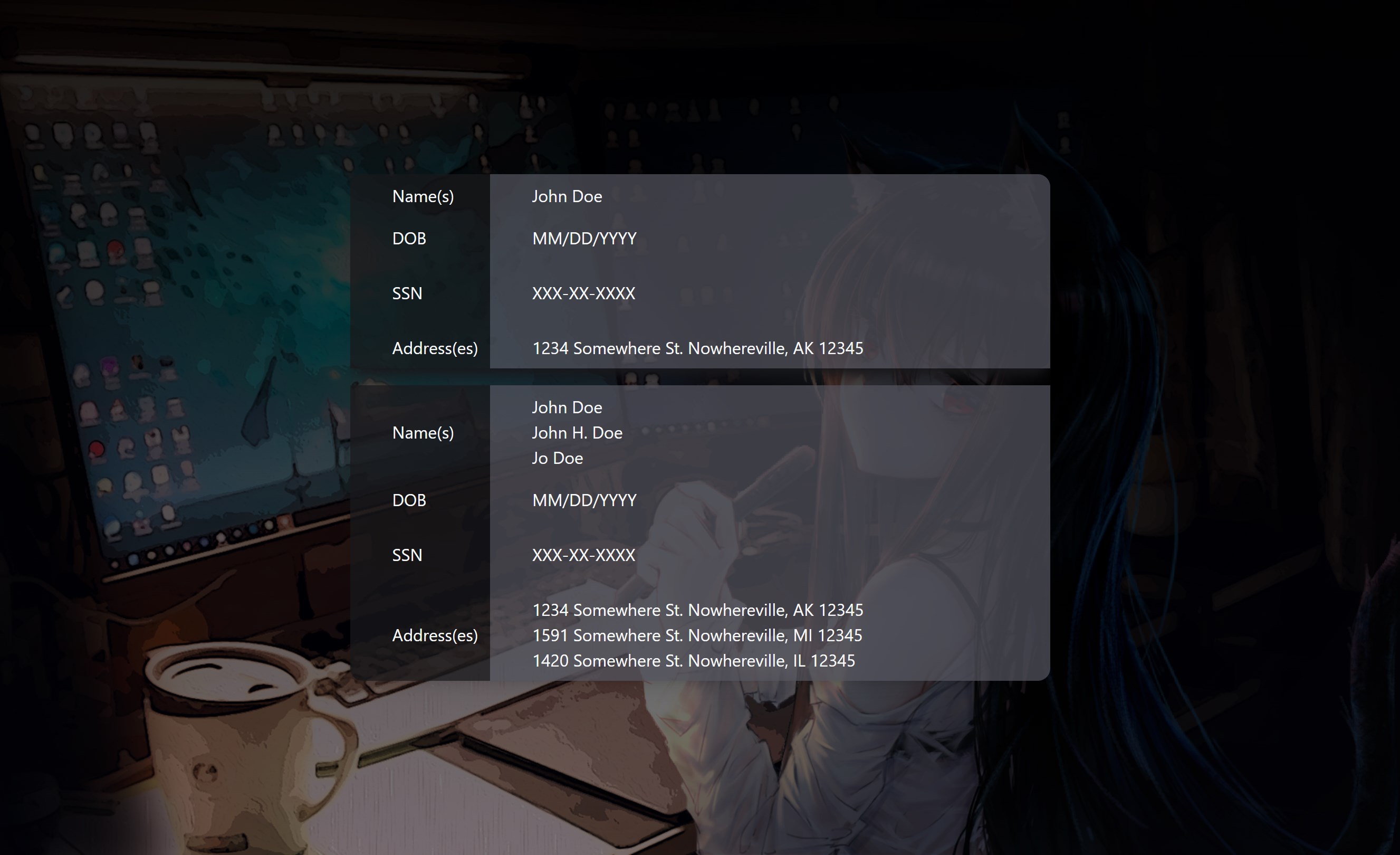
With a bit of effort and migraines from dealing with CSS, I ended up with what I feel is a clean and useful interface. Eventually, I’ll be adding phone number searches, results filtering and sorting, and a way to select and export results. But for now, this is working perfectly fine with a simple Ctrl-F to find the exact entries I need.
Querying nearly three billion documents, around 320 GB once indexes are included, takes under a second (including page generation) on my 2019 PC built for machine learning. Nothing special - not a ton of RAM or a top-of-the-line CPU.
The search page utilizes Express.js and does a simple query that, because of the way MongoDB works, uses the indexes to drastically increase speed and performance. The results of that query are sent to the results page, which formats data (such as dates, phone numbers, socials, etc.) accordingly. Each card it creates shows the rows of data that are included in the document - nothing more. Then it condenses documents based on the SSN number.
Future Enhancements and Reflections
As I continue refining this tool, I’m considering adding more advanced features like cross-database querying, automated data analysis, and potentially even some basic AI to predict patterns in the data. For now, though, I’m just thrilled to have a working system that I can use to dive into this massive dataset.
This project has reminded me why I fell in love with data hoarding and analysis in the first place. There’s something incredibly satisfying about bringing order to chaos, even if that chaos is 750 GB of stolen data. It’s a strange hobby, sure, but it’s mine, and it’s one that keeps me both entertained and constantly learning.
If you’re interested in diving into a similar project, I encourage you to try it out. The educational value is immense, and you’ll come away with a much deeper understanding of data structures, querying, and the ethical implications of handling sensitive information.